by Niko Gamulin
by Niko Gamulin
Diabetic retinopathy detection with convolutional neural network
Diabetic Retinopathy Detection on Kaggle has ended recently. As California Healthcare Foundation has provided huge dataset of retina images, I considered it a perfect chance to test scientific concepts on real data. Given the images for which a clinician has rated the presence of diabetic retinopathy on a scale from 0 to 4 (No DR, Mild, Moderate, Severe, Proliferative DR), the aim of the competition was to provide a model whcih can determine the presence of retinopathy automatically, without doctor’s assistance.
As researchers at Harvard Medical School have created a smartphone-based eye examination kit for use with iPhone and Android devices, the competition is not only an opportunity to practice AI. Personally I believe the models developed in scope of competition will directly contribute to the improvement of public health and this was the main reason I decided to give it a try.
For this competition I have used Caffe deep learning framework and GeForce GTX 980 GPU. The code has been written in python and is available on github repository. I hope the code could be helpful to anyone working in similar field.
Model Architecture
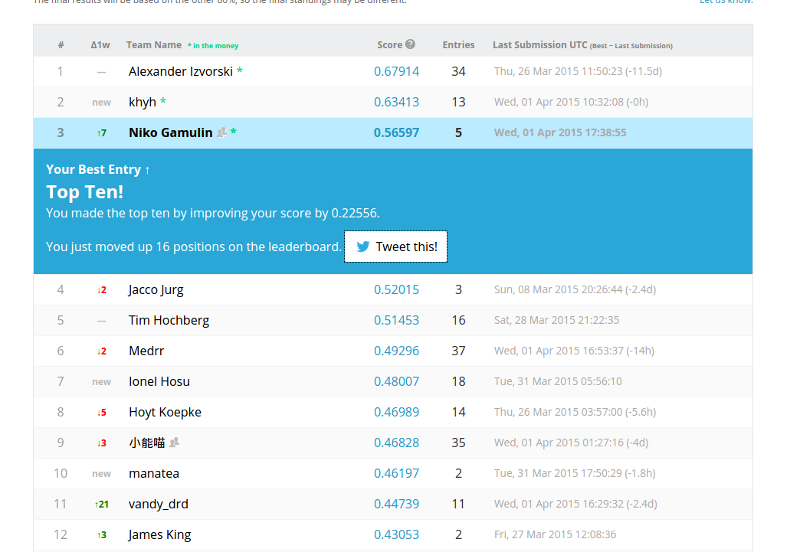
Pragmatic approach
After reading a number of articles from the field I believe there are many things yet to be scientifically explained. I have had several question during the development of the model for which I still haven’t found the explanations, such as how to set the optimal kernel size given the semantic properties of examined data, how to select optimal number of kernels and how to select the number of layers, to name a few. Regarding the number of layers, there are some general guidelines, but I think the majority of practitioners have achieved their results with pragmatic approaches.
One question that I found an explanation for in Geoffrey’s Hinton article is what is the idea behind using rectified linear units instead of sigmoid.
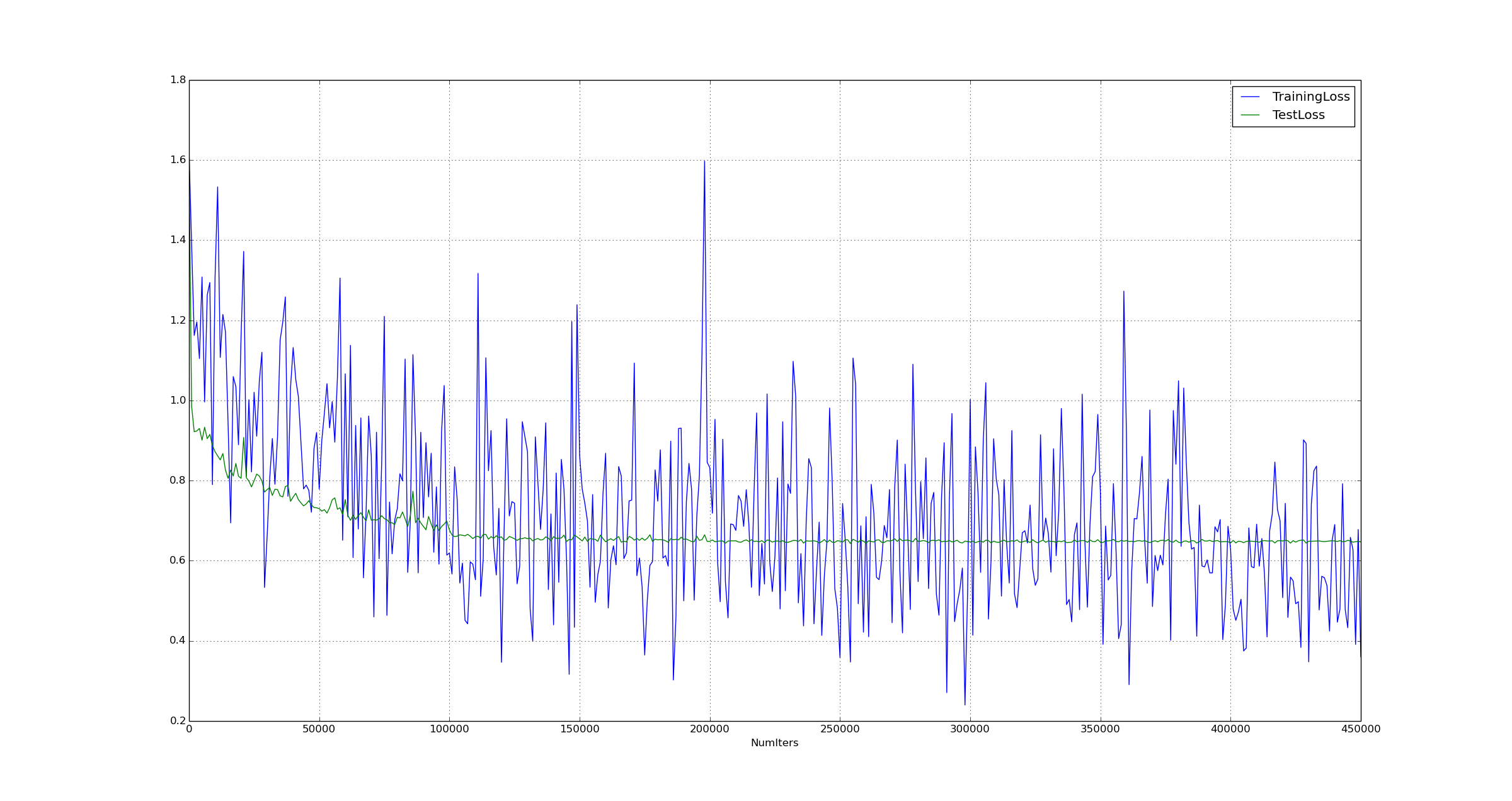
Anyway, I tried to combine the findings from the articles with pragmatic augmentation of the dataset with elastic distortions and bias-variance error diagnosis; If the bias was large I made the model more complex and if the variance was large, I reduced the model complexity. Below is the image that shows the training and test error of the model which performed the best:
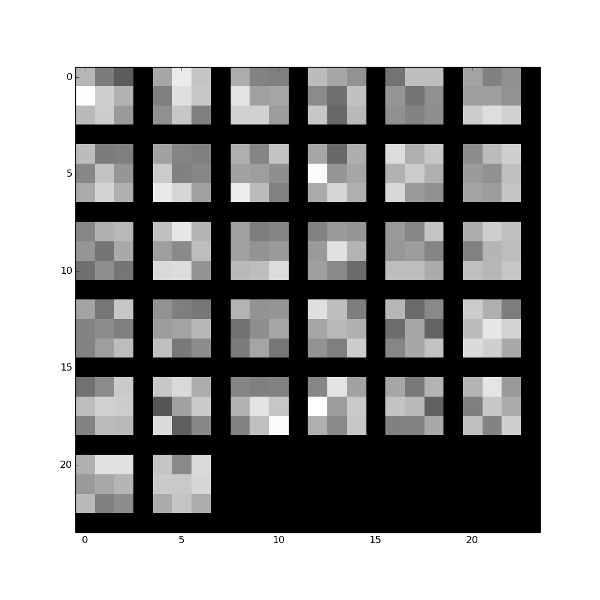
Learned filters
Below are some images of self-learned filters and their responses.
Convolutional Layer 1:
Convolutional Layer 2: